AI-agent governance & evidence
Govern AI-agent actions before they execute.
Magenta Canon gives teams a private control layer for policy-gated agent/tool operations, evidence capture, and audit-ready review.
Magenta Canon is active. Evaluation access is private — via a controlled portal and a design-partner process.

The problem
AI agents are moving from chat to action
Agents can call tools, touch data, change systems, and trigger workflows. When an agent takes a real action, two questions get hard fast: was it authorized, and can you prove what was allowed, blocked, and why?
Most teams cannot answer that today. The system that acts is also the system that writes the log — so the record can't be trusted on its own.
What it does
A control layer in front of agent actions
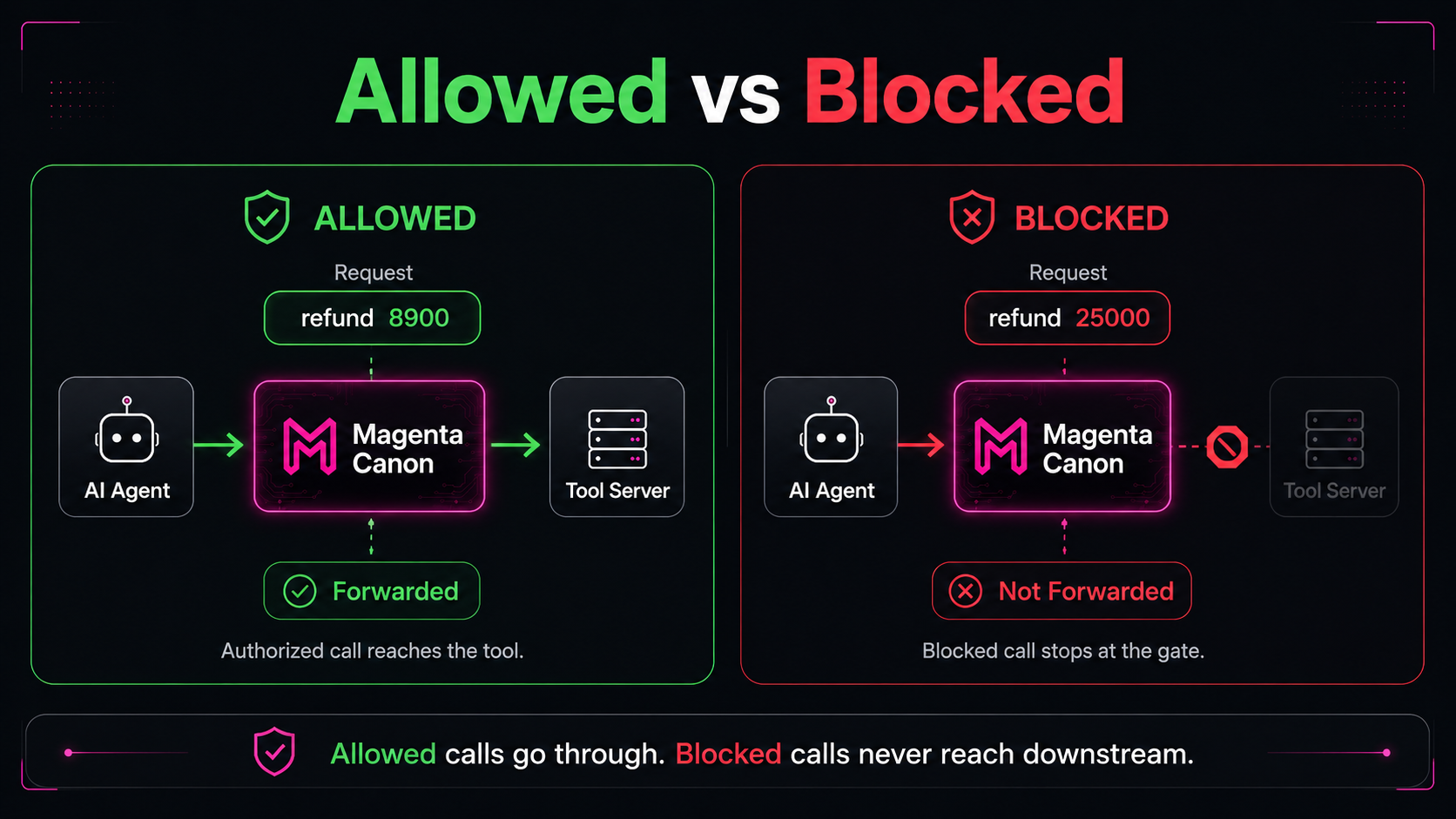
- Default-deny action gate — tool/agent calls are checked against policy before they run; unauthorized actions are stopped.
- Policy-bound execution — only delegated, in-scope actions proceed.
- Identity-aware decisions — each decision is bound to the acting principal.
- Evidence for allowed and blocked actions — both outcomes are recorded, not just successes.
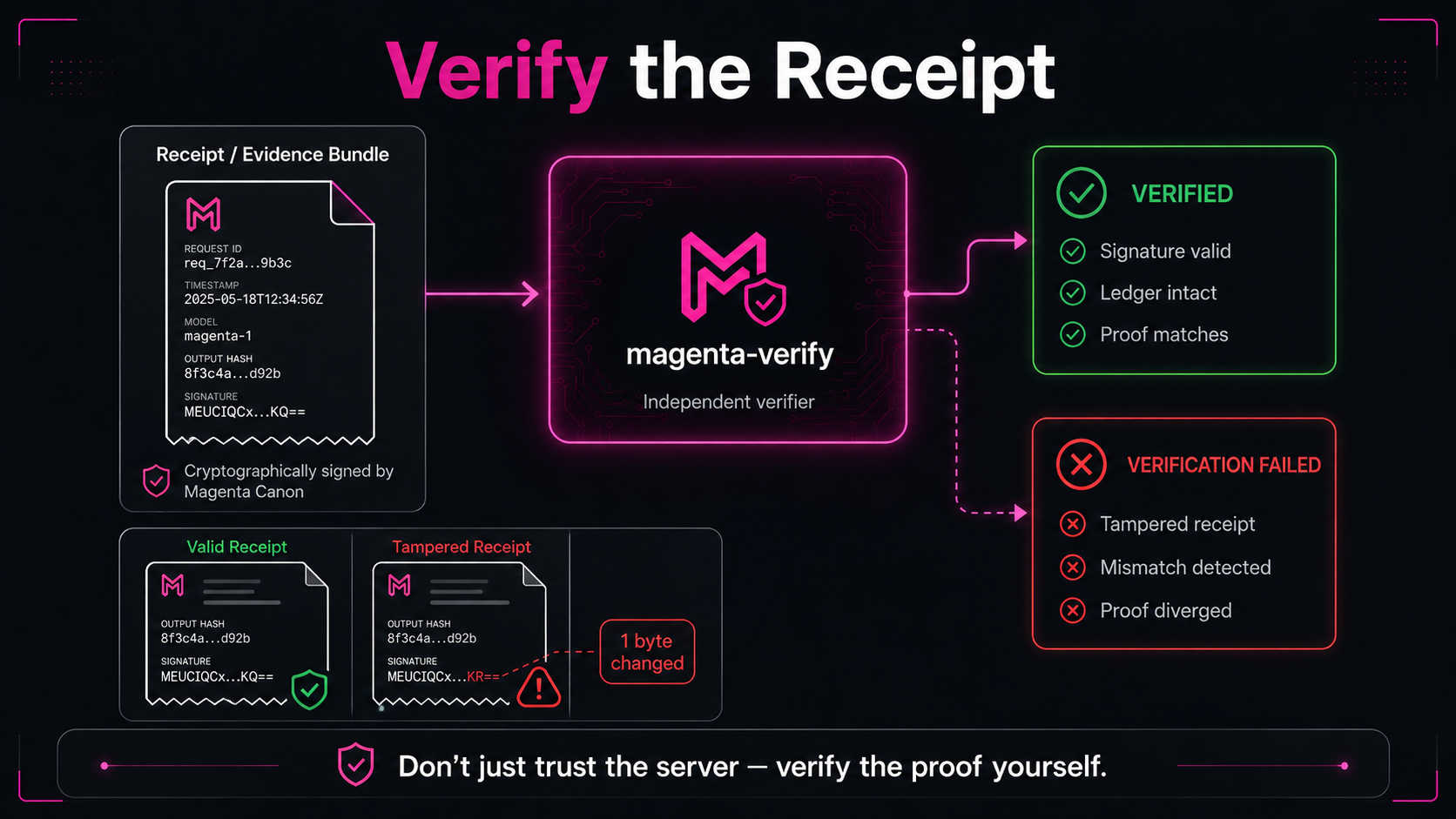
- Tamper-evident receipts for governed decisions — records are independently checkable; alteration is detectable.
- Review packets — forwardable evidence for security and compliance teams.
Who it's for
Built for the people accountable for agent risk
For CISOs & governance leads
Provable accountability for agent actions — what was allowed, what was blocked, and why — with tamper-evident evidence and audit-ready review packets. Reduce the risk of an agent taking an unauthorized, high-consequence action.
For platform & security engineers
A control layer in front of agent/tool execution with identity-aware, policy-bound decisions. Evaluate privately in the portal, review captured decisions and evidence, and compare blocked-call receipts against a downstream tool log to prove blocked calls never reached the tool. Magenta verifies the authorization path; downstream responses and results are evidence only when separately captured by an integration.
Understand it visually
Authorize what's allowed, block what isn't, record proof of both


Private evaluation
Evaluate Magenta Canon with us
Access is currently private. Authorized users review policy decisions, captured evidence, and evaluation materials inside a controlled portal — no public package dependency required.
- Invite-only portal for evaluation and evidence review.
- Design-partner onboarding tailored to your agent/tool workflows.
- Forwardable evaluation packets for internal security and compliance review.
Portal sign-in is for authorized users only.
Package status: public npm package access is paused pending IP/licensing review. Do not rely on prior public npm packages for production use.